Surveiller votre cluster Kubernetes et vos applications avec kube-prometheus-stack

Introduction
Il y a quelques mois, j'ai migré définitivement tous mes services (blog, git, etc.) que j'auto-héberge de la technologie docker-compose à Kubernetes en utilisant la solution K3S. Ce changement m'a demandé un certain nombre de modifications : créer des objets Deployment, Service, Ingress et j'en passe, nécessaires au bon fonctionnement des applications à déployer.
De plus, je me suis également basé sur des charts Helm publics dans le but de gagner du temps en personnalisant certains paramètres. L'objectif aujourd'hui est de vous présenter un chart très complet qui s'appelle kube-prometheus-stack anciennement baptisé prometheus-operator.
Ce chart permet de déployer de nombreux objets Kubernetes reliés à trois outils principaux :
- Prometheus : Outil de surveillance qui collecte et stocke des métriques provenant de diverses sources ayant comme capacité de lever ou non des alertes suivant la santé des serveurs, services ou applications observés ;
- Grafana : Plateforme de visualisation de données qui s'intègre avec Prometheus, permettant de créer des tableaux de bord afin d'offrir une vue graphique ;
- Alertmanager : Composant qui est aussi en relation avec Prometheus qui propose l'envoi de notification à la suite du déclenchement d'une alerte.
Pourquoi avoir choisi ces outils ? Ils sont tous les trois open source et Prometheus est référencé auprès de la CNCF (Cloud Native Computing Foundation) au statut Graduated depuis 2018. C'est donc une solution mature qui a fait ses preuves dans des contextes de production notamment.
Pour finir, le but de cet article est non seulement d'installer kube-prometheus-stack mais aussi de voir l'ensemble des étapes nécessaires pour superviser une application.
Prêt pour l'installation ? C'est parti !
Mise en place du chart
Comme pour tout chart Helm, vous aurez besoin du client helm sur votre poste afin de pouvoir dialoguer avec votre cluster et installer kube-prometheus-stack.
Avant d'installer quoi que ce soit, pour ceux qui sont sur K3S comme moi, je vous recommande de désactiver certaines règles de Prometheus qui sont par défauts et que ce dernier ne pourra pas surveiller, car certains composants Kubernetes ne sont pas sous forme de Pod avec K3S. C'est le cas du controller manager, kube-proxy et scheduler.
Voici un extrait de mon values.yaml qui a pour but de surcharger les valeurs par défaut du chart :
defaultRules:
rules:
kubeControllerManager: false
kubeProxy: false
kubeSchedulerAlerting: false
## Disabled PrometheusRule alerts
disabled:
KubeControllerManagerDown: true
KubeProxyDown: true
KubeSchedulerDown: true
On désactive ces trois règles par défaut, mais aussi la création des objets PrometheusRule pour ces trois composants. En effet, ce chart va créer plusieurs CRD (CustomResourceDefinition) comme l'objet PrometheusRule qui a pour but de déployer des règles dans Prometheus qui seront chargées directement dans la configuration principale.
kube-prometheus-stack déploie entre autre un opérateur Kubernetes, il va donc constamment surveiller certaines objets comme les PrometheusRule de manière à alimenter la configuration de Prometheus.
Exemple ici avec une règle déployée automatiquement qui surveille les erreurs au sein de la configuration de Prometheus :
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
[...]
spec:
groups:
- name: prometheus
rules:
- alert: PrometheusBadConfig
annotations:
description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to
reload its configuration.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/prometheus/prometheusbadconfig
summary: Failed Prometheus configuration reload.
expr: |-
# Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(prometheus_config_last_reload_successful{job="kube-prometheus-stack-prometheus",namespace="kube-prometheus-stack"}[5m]) == 0
for: 10m
labels:
severity: critical
Du côté de Grafana, j'ai fait aussi quelques modifications :
- Modification du fuseau horaire
- Désactiver la mire d'authentification et donner l'autorisation aux utilisateurs anonymes de visualiser l'ensemble des tableaux de bord. Rassurez-vous, l'objectif est de sécuriser l'accès à Grafana avec du mTLS au sein d'un
Ingressplutôt qu'utiliser un couple utilisateur / mot de passe.
Si vous souhaitez faire de même, voici les valeurs à modifier :
## Using default values from https://github.com/grafana/helm-charts/blob/main/charts/grafana/values.yaml
##
grafana:
## Timezone for the default dashboards
## Other options are: browser or a specific timezone, i.e. Europe/Luxembourg
##
defaultDashboardsTimezone: Europe/Zurich
grafana.ini:
auth.anonymous:
enabled: true
org_role: Viewer
auth:
disable_login_form: true
Dernière partie, la configuration d'Alertmanager. Cette dernière est un peu spécifique et peut contenir des informations sensibles. Dans mon cas, j'utilise Telegram pour être notifié en cas d'erreur. Je dois donc renseigner une clé d'API dans la configuration. C'est pourquoi je préfère injecter la totalité de la configuration sous forme de secret comme ceci :
## Configuration for alertmanager
## ref: https://prometheus.io/docs/alerting/alertmanager/
##
alertmanager:
## Settings affecting alertmanagerSpec
## ref: https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#alertmanagerspec
##
alertmanagerSpec:
## ConfigSecret is the name of a Kubernetes Secret in the same namespace as the Alertmanager object, which contains configuration for
## this Alertmanager instance. Defaults to 'alertmanager-' The secret is mounted into /etc/alertmanager/config.
##
configSecret: alertmanager-config
Je dois évidemment créer le secret alertmanager-config en amont avec comme clé alertmanager.yaml et la configuration en base64.
Pour vous donner des exemples de configuration et l'ensemble des paramètres pouvant être utilisés, je vous recommande ce lien de la documentation officielle.
L'ensemble du paramétrage ci-dessus n'est aucunement obligatoire. Vous pouvez très bien laisser la configuration par défaut.
Tout est bon ? il est temps d'installer notre chart !
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# Avec fichier values.yaml
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --namespace kube-prometheus-stack --create-namespace -f values.yaml
# Sans fichier values.yaml
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --namespace kube-prometheus-stack --create-namespace
Nos Pod s'exécutent sans erreur, tout est bon ! Maintenant, comment faire pour surveiller nos applications ?
Surveiller vos applications ou vos services
Dans la partie précédente, nous avons vu ce qui concerne l'installation du chart kube-prometheus-stack, comme dit précédemment ce chart embarque plusieurs éléments par défaut donc des règles Prometheus et des tableaux de bord Grafana pour l'orchestrateur Kubernetes.
Je vous laisse le soin de créer des Ingress pour Prometheus, Grafana et Alertmanager pour rendre visible leurs interfaces graphiques sinon, vous pouvez faire du port-forward pour les consulter de manière temporaire.
Néanmoins, le chart ne va pas surveiller automatiquement vos applications ou vos services, il faudra venir créer et configurer plusieurs objets.
Dans cette partie de l'article, je vous propose comme fil rouge le fait de vouloir surveiller une base de données PostgreSQL que l'on peut installer avec le chart de Bitnami. Ce chart doit exposer un service permettant d'exposer des métriques. Vous pouvez le faire en surchargeant certains paramètres avec un fichier values.yaml comme celui-ci :
metrics:
## @param metrics.enabled Start a prometheus exporter
##
enabled: true
Ajouter un ServiceMonitor pour surveiller notre application
Le ServiceMonitor est un autre objet CRD créé en déployant le chart. Dans ce ServiceMonitor, l'objectif est de donner toutes les informations nécessaires à l'opérateur Prometheus pour initialiser la configuration de Prometheus qui viendra récupérer les métriques via le Service de l'application à surveiller, dans notre cas PostgreSQL.
Voici un exemple de ServiceMonitor :
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
release: kube-prometheus-stack
name: postgresql
namespace: kube-prometheus-stack
spec:
endpoints:
- port: http-metrics
namespaceSelector:
matchNames:
- postgresql
selector:
matchLabels:
app.kubernetes.io/component: metrics
app.kubernetes.io/instance: postgresql
Quelques petites subtilités sont à connaître :
- Le ServiceMonitor se déploie dans le même namespace que là où vous avez installé le chart kube-prometheus-stack ;
- Le label
release: kube-prometheus-stackest obligatoire pour que le ServiceMonitor soit surveillé par Prometheus. Néanmoins, il est possible de modifier cette configuration dans le chart de kube-prometheus-stack avec le paramètreserviceMonitorSelectorNilUsesHelmValues: false; - Partie endpoints, http-metrics est le nom du port au sein du Service PostgreSQL qui expose les métriques ;
- Partie namespaceSelector dans matchNames, il est important de spécifier le nom du namespace de PostgreSQL contenant le service ;
- Partie selector, les labels sont ceux du Service PostgreSQL qui expose les métriques.
Une fois le ServiceMonitor créé, vous devriez voir le point de terminaison au sein de l'interface de Prometheus :
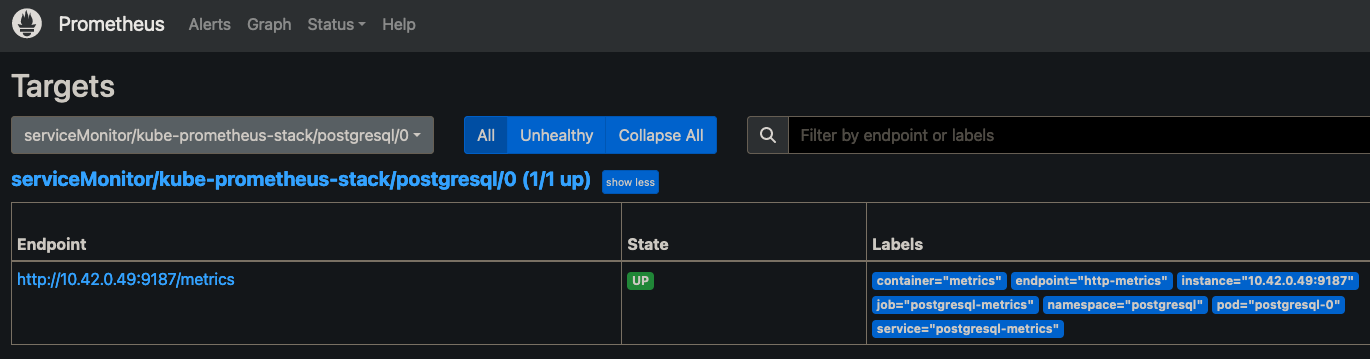
Créer des règles avec l'objet PrometheusRule
Avec le ServiceMonitor, Prometheus récupère nos métriques par intervalles réguliers. Il convient maintenant de créer des règles pour notre base de données PostgreSQL de manière à détecter des comportements anormaux.
Plutôt que d'écrire ces règles en partant de zéro, je vous conseille ce site : Awesome Prometheus alerts. Il concentre une multitude de règles en fonction de plusieurs catégories de services ou d'applications.
Voici un exemple de fichier YAML avec l'objet PrometheusRule et la première règle Prometheus PostgreSQLDown :
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
release: kube-prometheus-stack
name: postgresql
namespace: kube-prometheus-stack
spec:
groups:
- name: PostgreSQL
rules:
- alert: PostgreSQLDown
annotations:
description: |-
PostgreSQL instance is down
VALUE = {{ $value }}
LABELS = {{ $labels }}
summary: PostgreSQL down (instance {{ $labels.instance }})
expr: pg_up == 0
for: 0m
labels:
severity: critical
[...]
Ici aussi, le label release: kube-prometheus-stack est obligatoire, à moins de modifier dans le chart le paramètre ruleSelectorNilUsesHelmValues avec une valeur à false.
Une fois l'objet PrometheusRule déployé dans le cluster, nos règles apparaissent dans l'interface de Prometheus :
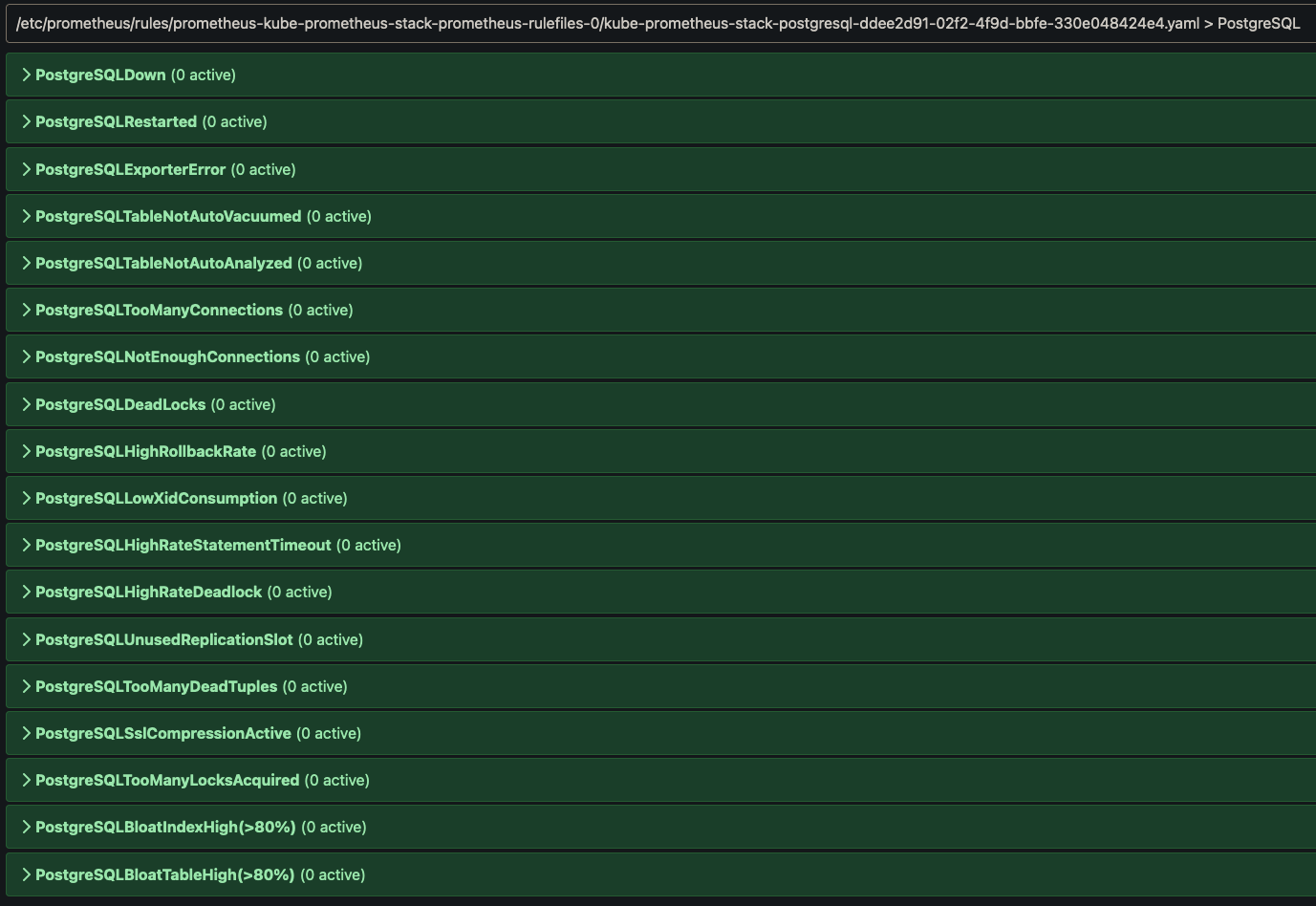
Configurer un tableau de bord dans Grafana
Dernière étape, l'aspect visualisation avec la création d'un tableau de bord dans Grafana.
Comme pour la partie du dessus, l'idée n'est pas de créer un tableau de bord en partant de rien. Grafana met à disposition plusieurs tableaux de bord préconstruits et facilement réutilisables.
Pour configurer un tableau de bord au sein de Grafana, pas besoin de créer d'objets spécifiques dans ce cas précis. Une ConfigMap suffit sans oublier d'initialiser le label grafana_dashboard: "1".
apiVersion: v1
data:
postgresql-dashboard.json: |-
[...]
kind: ConfigMap
metadata:
name: postgresql-dashboard
labels:
grafana_dashboard: "1"
Récapitulatif
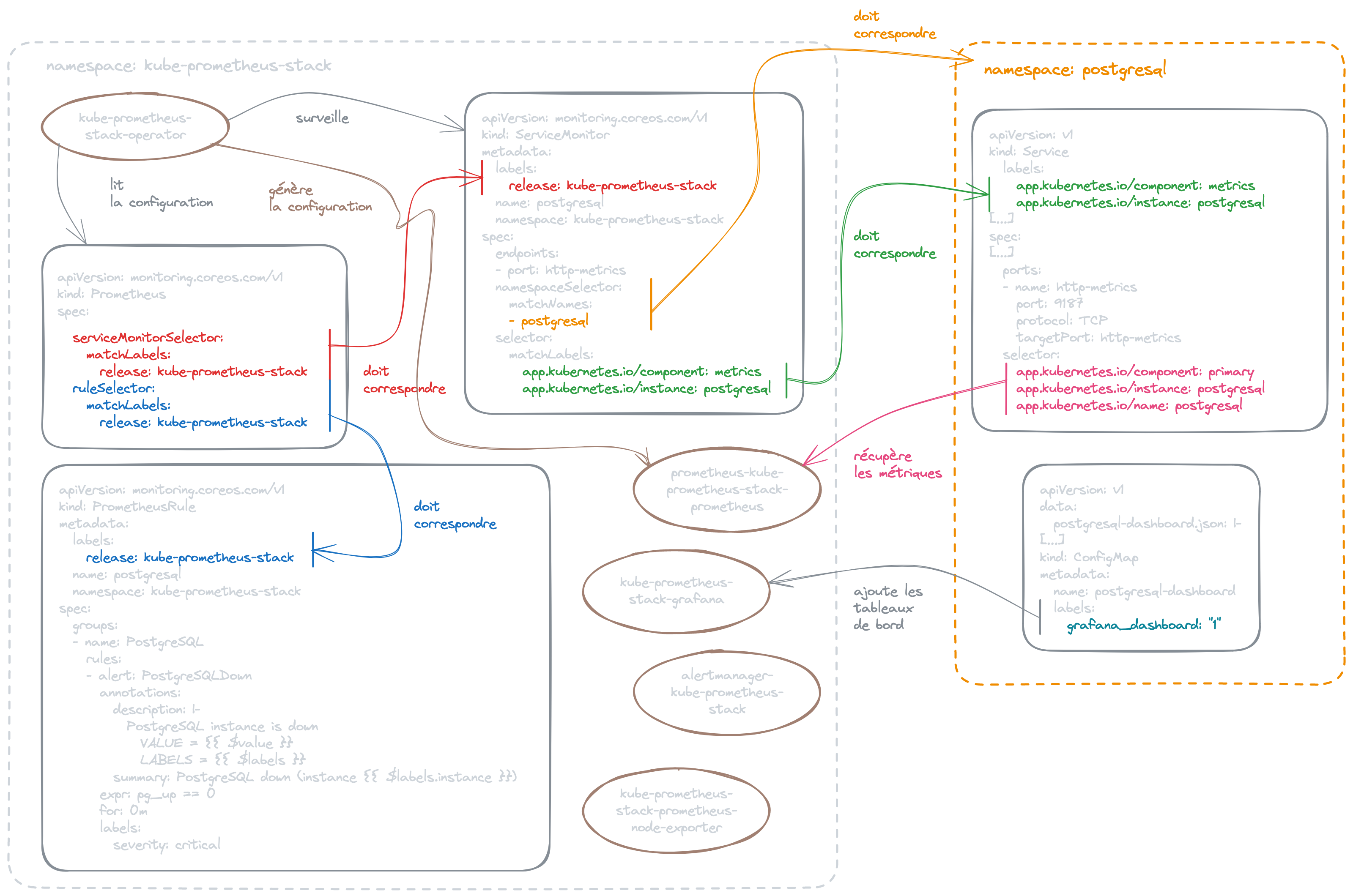
Voici un schéma qui regroupe l'ensemble des actions nécessaires pour surveiller vos applications dans Kubernetes. Je me suis basé sur un schéma d'OpenShift que j'ai enrichi notamment avec les PrometheusRule et les ConfigMap pour les tableaux de bord de Grafana.
Le mot de la fin
Bâtir une plateforme de supervision n'est pas chose aisée, même en se basant sur des règles Prometheus ou tableaux de bord Grafana proposés par la communauté, cela demandera de l'affinage au cours du temps. Notamment pour ce qui est d'ajuster les seuils pour déclencher ou non des alertes.
Néanmoins, cette trousse à outils kube-prometheus-stack composé de Prometheus, Grafana et Alertmanager permet d'obtenir très rapidement un résultat concluant tout en utilisant plusieurs solutions qui sont référencées comme standard du marché.
J'ai trouvé intéressant de faire un article dessus notamment pour montrer l'ensemble des étapes nécessaires pour superviser vos applications de bout en bout.