Quelques bonnes pratiques à mettre en place quand on fait du Terraform


Introduction
Que ce soit dans des contextes On-Premise ou Cloud, il est difficile de ne pas parler de Terraform quand on souhaite réaliser la création automatisée d'une infrastructure. À l'époque, même sans version majeure, Terraform s'est imposé comme un standard notamment grâce à sa capacité de gérer le cycle de vie des ressources déployées tout en associant une grande traçabilité et reproductibilité grâce au côté "code".
Même si dernièrement Hashicorp, son éditeur, a changé la licence de ce dernier, Terraform reste gratuit pour une large majorité du public qui ne vend pas de solutions commerciales associées à cet outil.
Suite à ce grand changement, la communauté s'est scindée en deux et c'est de cette façon qu'OpenTofu est né. Il garantit une compatibilité avec Terraform depuis la version 1.6.0 mais petit à petit, proposera des fonctionnalités bien distinctes qui sont très attendues : c'est le cas du chiffrement du State qui sera proposé avec la 1.7.0.
Peu importe que vous utilisiez Terraform ou OpenTofu, l'écriture du code est quasiment similaire. C'est pourquoi dans cet article, je vais vous détailler plusieurs bonnes pratiques à mettre en place quand on utilise ce type de solution d'infrastructure as code.
Il est tellement important de réfléchir à la manière de concevoir le code Terraform, celui-ci doit être le plus évolutif possible tout en intégrant les contraintes et les normes du langage.
À des fins d'illustration, je vais donner quelques exemples sur les trois fournisseurs de Cloud principaux, à savoir : Google Cloud, AWS et Azure.
Enfin, je ne rentre pas plus en détail sur le fonctionnement de Terraform, je l'avais déjà présenté dans des articles précédents.
Le code Terraform reste du code
Bien que le but principal de Terraform reste de déployer de l'infrastructure de manière déclarative, le code écrit doit être soumis aux mêmes exigences qu'un code de développement classique comme le Java ou le Go.
C'est pourquoi, je vous recommande d'intégrer dès la première ligne de code, des outils permettant de vérifier le respect des bonnes pratiques voire même des tests unitaires.
Il y a quelques mois en arrière, j'avais réalisé un article sur GitLab CI et la mise en place de Terraform en détaillant plusieurs petits outils réalisant ce genre de vérifications. Je vous recommande de le lire pour vous donner un aperçu des composants que j'ai l'habitude de mettre en place pour augmenter de manière générale la qualité du code et éviter l'introduction de failles de sécurité côté infrastructure.
Honnêtement, ces outils de vérifications syntaxiques sont très peu coûteux à mettre en place et permettent de rester dans les standards du langage. Si vous souhaitez les introduire plus tard dans le développement de votre infrastructure, la dette technique ne sera que plus grande !
Mono repo ou multi repos ?
Dès lors que l'on commence un projet avec Terraform, il y a une question qui revient assez souvent : "Plutôt mono repo ou multi repos ?"
Avec un peu de recul, je peux dire qu'il n'y a pas vraiment de bonnes réponses et que cela dépend essentiellement de la configuration de l'équipe qui doit développer et maintenir le code Terraform.
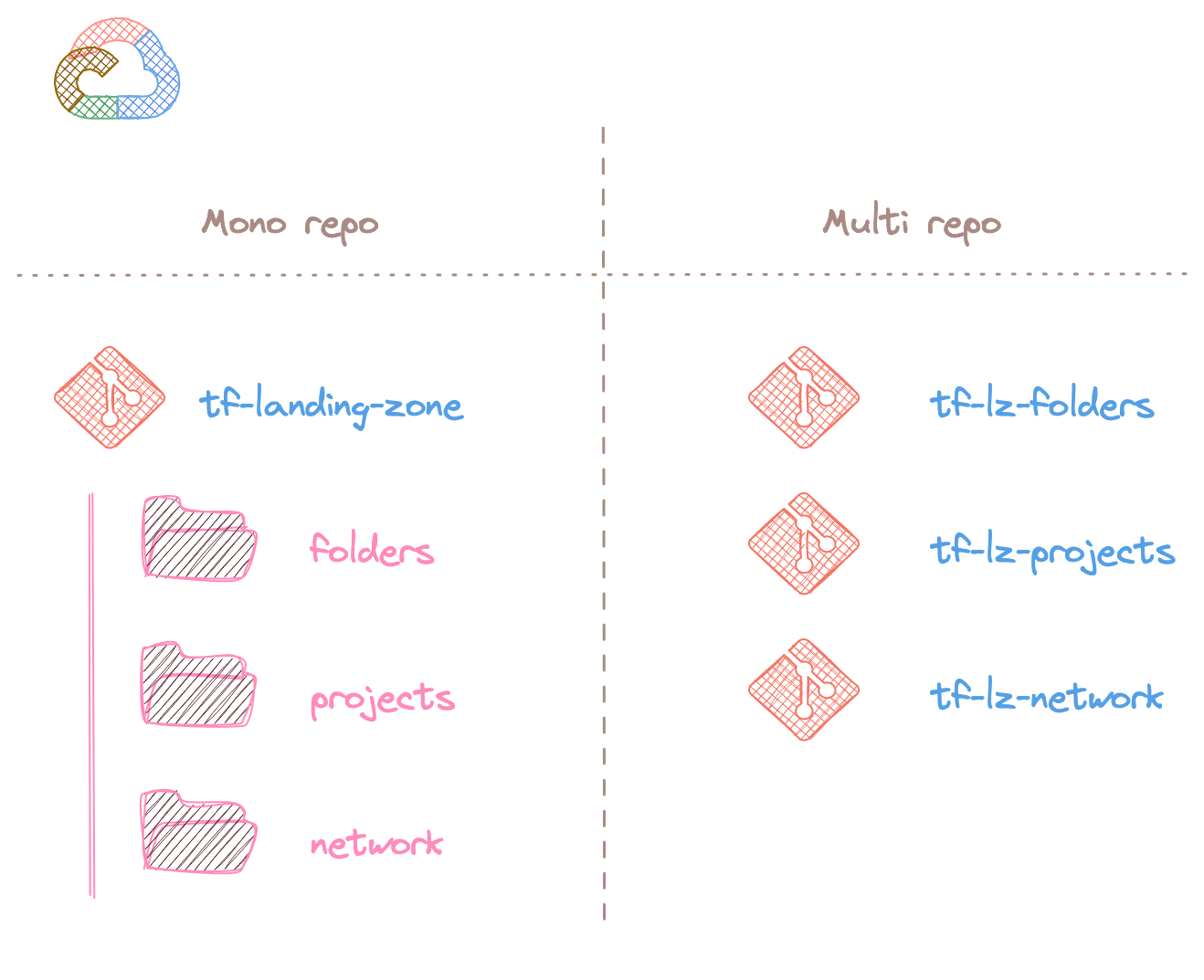
Le cas assez classique est la construction d'une Landing Zone, peu importe le fournisseur de Cloud. C'est généralement une seule et même équipe qui va gérer la mise en place de l'organisation (structure, gestion des droits, etc.) et l'architecture réseau en découlant.
Il est peut-être plus pertinent d'avoir un mono repo pour ce cas d'utilisation, plusieurs avantages peuvent être cités :
- Centralisation de toute l'infrastructure, le dépôt de code Git devient la source de vérité de l'infrastructure déployée ;
- Une seule et même CI/CD permettant d'effectuer les mêmes vérifications et tests quelle que soit la couche d'infrastructure déployée ;
- Une vue centralisée là aussi côté CI/CD pour faire le plan et l'apply, cela permet aussi de voir les dérives d'un coup d'œil.
Néanmoins, si l'équipe réseau est totalement séparée de celle gérant l'organisation Cloud, il peut avoir un intérêt à découper ces deux parties :
- Meilleure gestion des droits des développeurs et isolation totale ;
- Versioning totalement indépendant.
Attention tout de même en cas de multi repos, d'avoir la même structure de code ainsi que les mêmes vérifications côté CI/CD pour garantir le même niveau d'exigence sur l'infrastructure !
À vous de décider en fonction de votre façon de travailler !
Structure de projet Git
Cas classique
Pour la structure du code, vous pouvez avoir autant de fichiers .tf que vous voulez. Gardez à l'esprit qu'une base minimale de fichiers est importante pour conserver une certaine homogénéité entre vos projets Git :
main.tf: Fichier principal pour déclarer vos ressources ;variables.tf: Fichier de déclaration de variables ;outputs.tf: Fichier de déclaration pour les blocsoutput;providers.tf: Permet de lister les providers Terraform et les contraintes au niveau des versions ;backend.tf: Configuration dubackendTerraform pour la gestion dutfstate, j'y reviendrai un peu plus loin.
L'objectif est aussi d'avoir un main.tf assez simple à lire. Je veux dire par là qu'il ne faut pas hésiter à décomposer vos ressources dans d'autres fichiers quand cela vous semble opportun.
Il peut être intéressant de découper les ressources associées au réseau à celles de calcul : on pourrait avoir un network.tf et un compute.tf, le main.tf. Ce dernier fichier pourrait contenir notre Resource Group dans le cas d'un code pour Azure.
Gestion des environnements
Dans le cas où l'on doit déployer les mêmes ressources dans différents environnements (développement, test, production, etc.), il est recommandé d'éviter autant que possible de dupliquer le code.
C'est pourquoi, il est préférable de s'appuyer sur un mécanisme intégré dans Terraform, les fichiers tfvars.
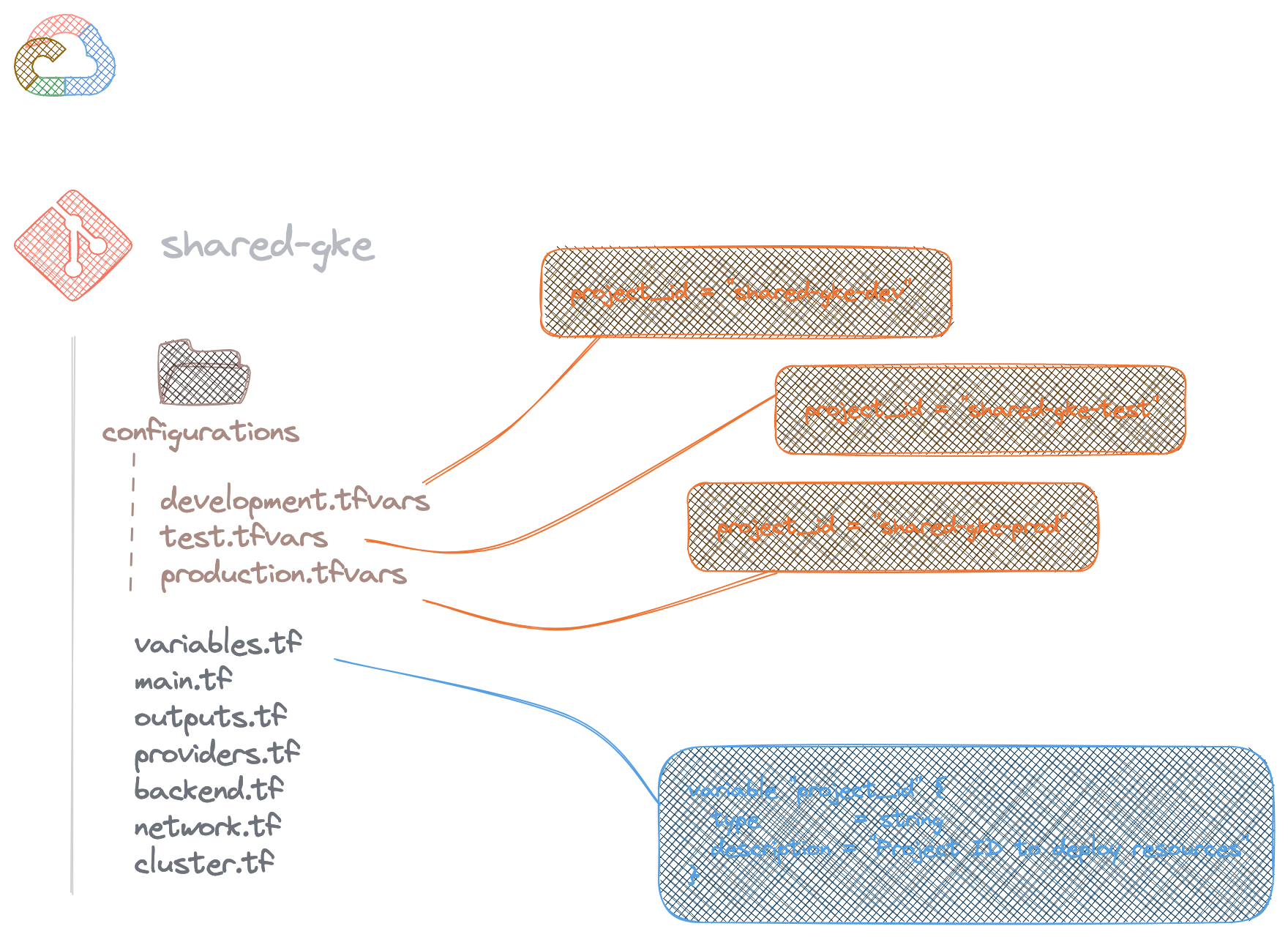
Dans cet exemple pour déployer une plateforme Google Kubernetes Engine, la gestion des environnements se réalise à travers trois fichiers .tfvars contenus dans le dossier configurations. De plus, un fichier correspond à un environnement de déploiement.
Le fichier variables.tf défini une variable project_id qui ne sera instanciée qu'à travers un de ces trois fichiers.
Cette approche demande de passer en paramètre le fichier pour que les instructions plan et apply s'effectuent. Exemple ici :
# Plan
terraform plan -var-file=./configurations/development.tfvars
# Apply
terraform apply -var-file=./configurations/production.tfvars
Enfin, il est recommandé de placer uniquement les variables qui sont dépendantes de l'environnement dans ces fichiers pour une meilleure lisibilité.
Règles de nommage
Définir une convention de nommage est très important pour déployer vos ressources de manière uniforme. Cela fait partie des pré-requis avant l'écriture du code. Que ce soit le nom de la ressource elle-même ou le suffix que toutes vos ressources vont devoir adopter.
Comment répondre à cette exigence ? Vous avez plusieurs possibilités :
- Définir vos règles en dur sur chaque ressource : pas du tout évolutif et ne permet pas de centraliser la convention d'une façon ou d'une autre ;
- Utiliser un provider dédié, par exemple pour Azure, le provider Terraform azurecaf remplit ce rôle : certainement la façon la plus aboutie et personnalisable, mais nécessite beaucoup d'écriture de code en amont pour parvenir à un résultat satisfaisant ;
- Utiliser un module, là aussi pour Azure, naming qui permettra via une déclaration assez simple de profiter des
outputsprédéfinis ; - Créer son propre module et le versionner de manière indépendante : Facile, rapide et totalement réutilisable.
Pour le quatrième point, je vais l'illustrer avec un exemple de code très rapide à mettre en place, inutile de construire un module trop conséquent :
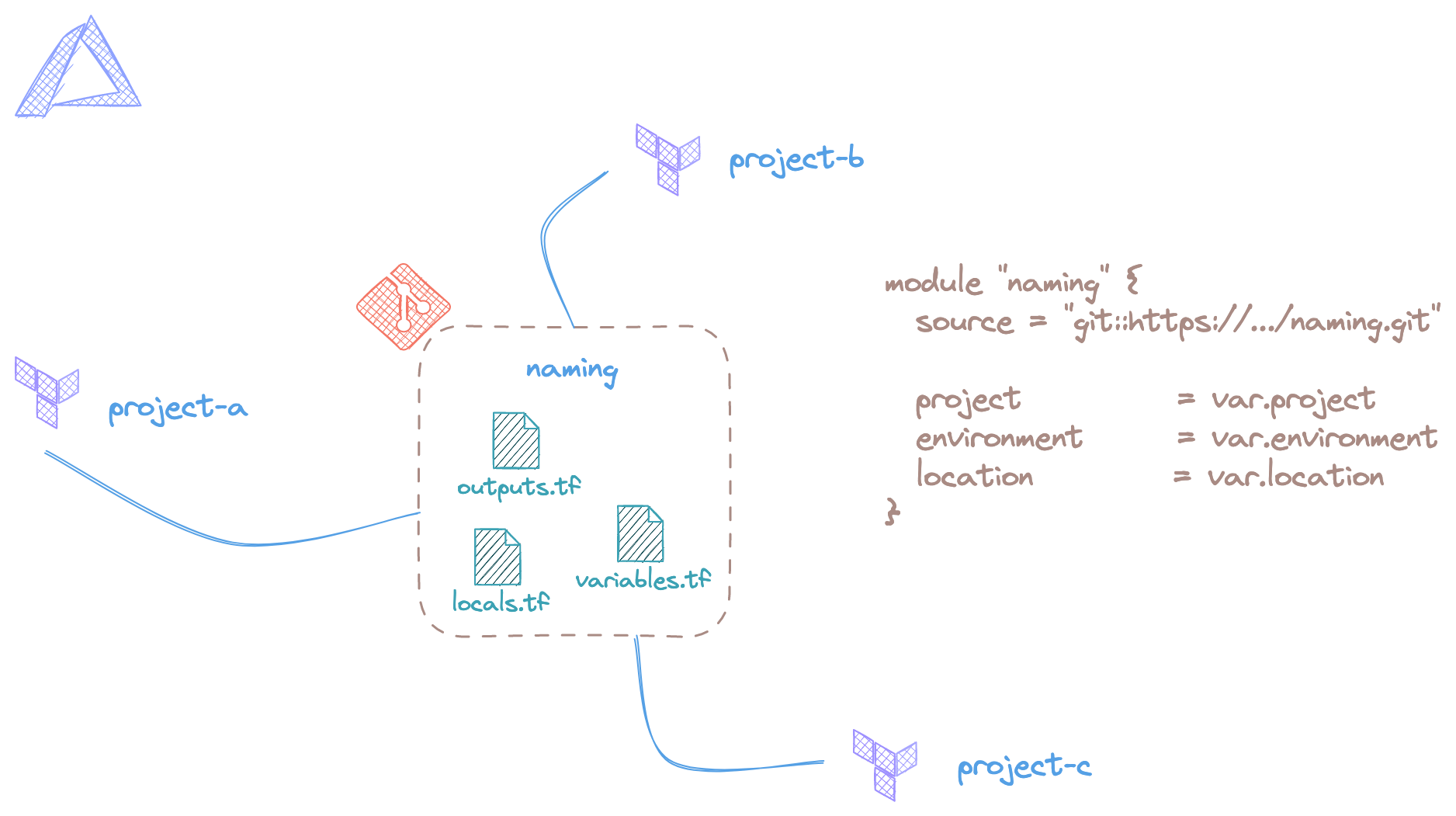
Le module présenté est contenu dans un dépôt de code Git qui peut être appelé par différents dépôts de code Terraform. La convention de nommage portée par ce dernier, a pour objectif d'être centralisée pour que celle-ci soit utilisée de manière globale.
Trois variables d'entrée peuvent être définies pour au sein d'un fichier variables.tf :
- project : le nom du projet à déployer ;
- environment : le type d'environnement que le projet utilise. Par exemple : dev, staging ou prod. À adapter selon le nom de vos environnements ;
- location : la région utilisée pour déployer les ressources du projet.
Ces trois informations permettront en plus du nom de la ressource, de nous donner un suffixe utilisable pour toutes nos ressources.
Au sein du code du module, le fichier principal sera un locals.tf. Exemple ici pour des ressources Azure :
locals {
services = {
"resource_group" = "rg"
"virtual_network" = "vnet"
[...]
}
suffix = "${var.project}-${var.environment}-${var.location}"
}
Bien évidemment, le but est de compléter la liste de services en fonction de vos besoins.
Il restera à définir dans le fichier outputs.tf les valeurs de services et suffix.
Une fois le module appelé dans le code, celui-ci est utilisable de cette manière :
resource "azurerm_resource_group" "main" {
name = "${module.naming.service["resource_group"]}-${module.naming.suffix}"
[...]
}
Voilà comment construire une convention de nommage facilement sans se casser la tête. Gardez à l'esprit que concevoir votre propre module nécessite de le maintenir et de gérer son cycle de vie ! J'entends par là : qualité de code, gestion des versions, etc.
Tags ou labels
Vos ressources peuvent porter des ensembles clé/valeur du nom de tag pour AWS et Azure ou label pour Google Cloud. Quel que soit le projet Terraform ou le module que vous êtes en train de construire, cette partie est très importante à des fins de traçabilité, mais surtout pour donner de la visibilité sur la facturation des ressources. C'est un des points remontés dans les bonnes pratiques du FinOps notamment.
En clair, vous devez rendre obligatoire une variable tags ou labels en entrée de votre code Terraform.
variable "tags" {
type = map(string)
description = "Map of tags for deployed resources"
}
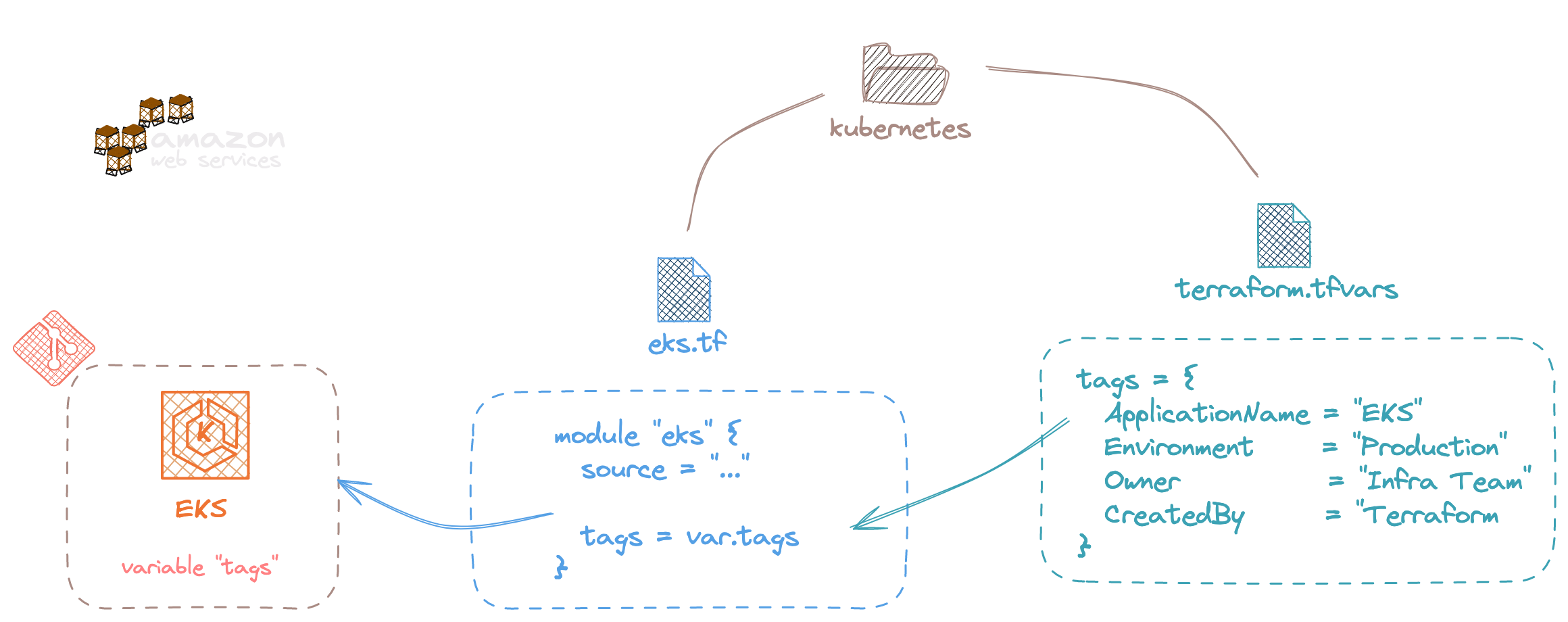
Exemple ici avec un module que l'on utilise au sein du code Terraform, les tags sont définis à travers un fichier terraform.tfvars et injecté dans le module.
Une bonne manière de procéder pour rendre les tags ou labels obligatoires et d'ajouter des Service control policies (SCPs) pour AWS permettant de bloquer la création de ressources en cas de tag manquant.
Tfstate externalisé
Le fonctionnement classique de Terraform repose sur la construction d'un fichier d'état appelé tfstate qui permet de répertorier toutes les ressources déployées, leurs caractéristiques, mais aussi les instructions outputs que vous avez définies. C'est en quelque sorte la mémoire de l'infrastructure gérée par Terraform.
Au lieu de stocker ce fichier dans votre dépôt Git, ce qui n'est définitivement pas une bonne idée surtout quand on travaille à plusieurs, il est recommandé d'externaliser la création de ce fichier en spécifiant un bloc backend.
En fonction des types de Cloud, différents services sont utilisés :
- Pour AWS, c'est S3 qui peut s'occuper de la partie stockage et Dynamo DB aura pour rôle de gérer le mécanisme de lock ;
terraform {
backend "s3" {
bucket = "tf-buckets-a3"
key = "landing-zone/network"
region = "eu-central-2"
}
}
-
Sur Azure, azurerm se base sur un Storage Account et un conteneur de type Blob pour y déposer le tfstate tout en gérant le mécanisme de lock nativement ;
-
Côté Google Cloud, c'est gcs autrement dit Google Cloud Storage qui permet, là aussi, de stocker l'état de Terraform et la gestion des locks.
Peu importe votre choix, il est vivement conseillé d'activer le versioning pour conserver vos tfstates à travers les modifications.
Dans un deuxième temps, plutôt que de fixer la configuration du backend en dur, il est recommandé de passer par un fichier de configuration .tfvars afin de rendre le paramétrage dynamique, notamment en fonction des environnements.
Pour cela, il est nécessaire de créer un bloc backend vide, comme celui-ci au sein du code :
terraform {
backend "azurerm" {
}
}
Puis de venir l'alimenter avec un fichier .tfvars contenant les différentes informations comme resource_group_name, storage_account_name, etc. pour Azure.
Enfin, lors de la phase d'initialisation, un argument supplémentaire sera nécessaire pour transmettre ces paramètres au bloc backend :
terraform init -backend-config=./configurations/production-backend.tfvars
Dans le cas d'un environnement de production.
Variables sensibles
Les variables sensibles ou confidentielles ne doivent en aucun cas être contenues ou stockées dans le code d'infrastructure, au risque de les diffuser très largement à travers Git.
Pour cela, plusieurs mécanismes existent :
-
Utiliser les variables de CI/CD : cas le plus rapide et facile à implémenter, ces variables peuvent stocker différents formats en fonction de l'outil utilisé ;
-
Configurer les solutions Cloud comme
Secret Manager(Google Cloud) pour stocker ce type d'information, tout peut se faire via des data sources du côté de Terraform ; -
Mettre en place une solution de type Vault, on part ici sur le cas le plus compliqué dans la mesure où l'outillage doit être installé, configuré, mis à jour et maintenu. Du côté de Terraform, là aussi, il est possible d'interagir avec des data sources.
À vous de choisir la solution la plus pertinente par rapport à votre utilisation.
Utiliser les mécanismes du langage
Sur Terraform, il est possible de créer des boucles ou des conditions pour rendre le code dynamique.
En ce qui concerne les conditions, seules les conditions ternaires sont disponibles. Ce qui limite grandement les possibilités !
Afin d'éviter de chainer un trop grand nombre de fois ce type d'expression, il est parfois plus pertinent d'utiliser des fonctions en utilisant des variables de type map. Exemple ici avec un cas simple de sélection de région sur Azure :
output "azure_region_v1" {
value = var.my_country == "france" ? "francecentral" : (var.my_country == "suisse" ? "switzerlandnorth" : (var.my_country == "etatunis" ? "eastus" : ""))
}
Ce qui devient vraiment compliqué à lire...
La version simplifiée ressemblerait à ça :
variables.tf
variable "azure_regions" {
type = map(string)
description = "Map of Azure regions"
default = {
"suisse" = "switzerlandnorth",
"france" = "francecentral",
"etatunis" = "eastus"
}
}
variable "my_country" {
type = string
description = "My country name"
}
outputs.tf
output "azure_region_v2" {
value = lookup(var.azure_regions, var.my_country, "")
}
La fonction lookup permet de rechercher une clé dans une map et de spécifier une valeur par défaut, ce qui limite dans notre cas l'utilisation des conditions.
Comme vous pouvez le voir, la lisibilité du code est augmentée et celui-ci devient bien plus simple à maintenir, notamment dans le cas où il est nécessaire d'ajouter une quatrième région !
De manière générale, les conditions doivent être utilisées avec l'instruction count pour créer ou non une ressource. Pour les autres cas, il y a souvent un autre moyen d'optimiser le code.
Le mot de la fin
Quand on parle de langage d'infrastructure as code, on a souvent tendance à oublier que ça reste du code et qui par conséquent, doit être pensé pour être le plus facilement maintenable et évolutif.
J'espère que ces différents points vous ont apporté quelques astuces sur la manière d'utiliser Terraform au quotidien.
Bien évidemment, cette liste n'est pas exhaustive, il y a tellement à dire sur un langage aussi complet. Néanmoins, j'ai essayé de vous exposer les points les plus pertinents.
Bonne rédaction de code !