Mettre à l'échelle facilement sur Kubernetes avec Keda

Introduction
Lorsque l'on déploie sur un cluster Kubernetes, on est souvent amené à choisir le nombre de replicas d'un pod quand on utilise un objet de type Deployment. Il n'est pas toujours évident de définir ce nombre en fonction de la charge de travail du pod en question.
Et parfois, pour des aspects économiques, on serait tenté de ne pas faire tourner le pod selon différentes plages horaires. Par exemple, sur un cluster de développement, on peut très bien imaginer que l'on souhaiterait couper les pods hors des heures de travail afin de réduire pourquoi pas la taille des noeuds du cluster voire de les éteindre si plus aucun pod ne s'exécute.
De plus, dans un autre cas de figure, on pourrait souhaiter aussi que ce nombre de replicas puisse varier en fonction de la charge de travail entrante. Ainsi, plus la file d'attente est conséquente, plus le nombre de replicas du pod doit être important pour gérer au plus vite cette charge.
C'est pourquoi j'ai choisi de vous présenter Keda qui permet d'ajuster le nombre de pods d'un cluster en fonction d'événements. Il a l'avantage d'être très léger, peu consommateur en ressources et fonctionnant sur tout type de cluster Kubernetes car il utilise et implémente l'Horizontal Pod Autoscaler qui est un standard en matière d'objet. De plus, il est référencé pour le moment, comme un projet "sandbox" du CNCF.
Architecture
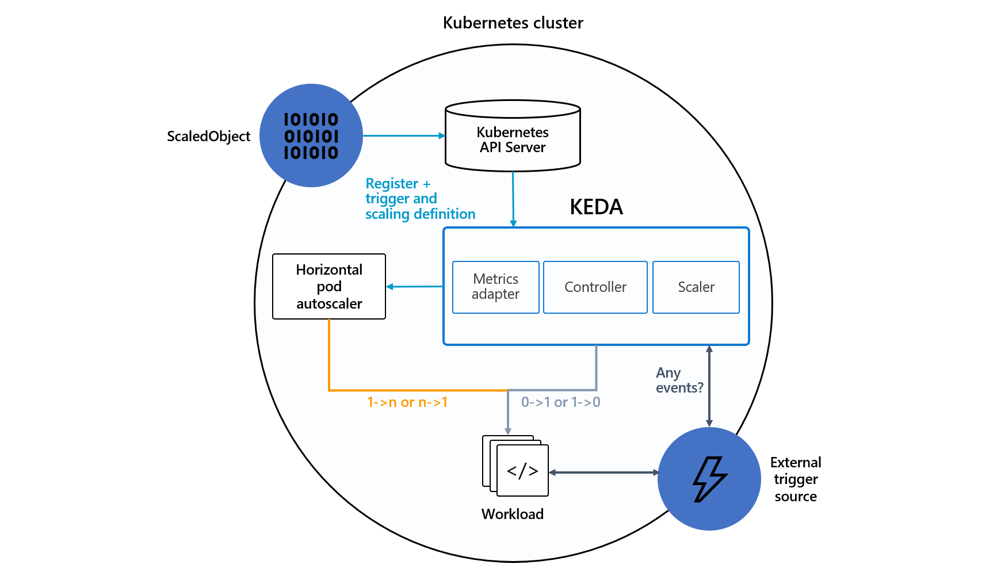
Keda possède trois gros modules : Metrics adapter, Controller et Scaler qui forment les principales briques de cet outil.
Keda possède énormément de scalers qui ont pour but de fournir des métriques afin de mettre à l'échelle différents types d'objets Kubernetes que vous pouvez voir à cette adresse. Plus tard dans l'article, le cron et rabbitmq seront tous les deux utilisés.
Plusieurs objets Kubernetes sont utilisés par cet outil :
- Les
ScaledObjectspermettent de lier un événement à unDeployment,StatefulSetou uneCustom Resource; - Les
ScaledJobslient un événement à un job Kubernetes ; - Ces deux objets peuvent utiliser des
TriggerAuthenticationouClusterTriggerAuthenticationpour gérer les questions d'authentification ou de secret avec la source des événements (par exemple RabbitMQ).
Installation
L'installation de Keda se fait de trois façons différentes, une par Helm (c'est celle que je recommande pour garder une trace sur la version), une autre via l'Operator Hub, et la dernière via un fichier Yaml qui contient l'ensemble des objets Kubernetes à créer.
Helm
Pour Helm, il faut préalablement ajouter le dépôt de charts suivant :
helm repo add kedacore https://kedacore.github.io/charts
Puis il faut synchroniser les dépôts :
helm repo update
Et pour finir, créer un namespace pour y installer Keda :
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
Operator Hub
Si vous souhaitez passer par l'Operator Hub, Keda propose un guide pour l'installation via ce lien.
Fichiers YAML
Si vous n'êtes pas familier avec les deux premières méthodes, vous pouvez installer Keda via les fichiers YAML, l'outil propose une ligne de commande rapide pour le mettre en place rapidement via le clonage du dépôt de code :
git clone https://github.com/kedacore/keda && cd keda
VERSION=2.2.0 make deploy
Démonstration
Eteindre le pod selon des plages horaires fixes
Tout d'abord il faut générer un déploiement de pod basique avec l'image nginx qui servira pour la suite.
kubectl create deploy nginx --image=nginx:1.19.10 --replicas=1 --dry-run=client -o yaml > deployment_nginx.yaml
Aperçu du deployment_nginx.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.19.10
name: nginx
resources: {}
status: {}
Vous pouvez voir dans le fichier deployment_nginx.yaml ce qui sera créé sur votre cluster Kubernetes. Une fois cela fait, il ne reste plus qu'à appliquer et créer nos objets.
kubectl create -f deployment_nginx.yaml
Ensuite, il va falloir utiliser un ScaledObject de keda de type cron qui possède l'ensemble des informations suivantes :
cat <<EOF | kubectl create -f -
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-nginx
spec:
scaleTargetRef:
name: nginx
triggers:
- type: cron
metadata:
timezone: Europe/Paris
start: 0 8 * * *
end: 0 19 * * *
desiredReplicas: "1"
EOF
Dans les metadatas, on repère plusieurs éléments, le nombre de replicas souhaité durant la période de temps choisi qui commence par start et se finit par end selon une timezone spécifique (ce qui évite les problèmes de décalage horaire).
De plus, le scaleTargetRef cible le nom du déploiement qui a été créé précédemment.
Il ne reste plus qu'à exécuter la commande :
kubectl create -f scaledobject_keda.yaml
Le pod nginx sera donc exécuté uniquement entre 8h et 19h, le nombre de replicas passera à 0 en dehors de ces horaires.
Si vous souhaitez plus d'informations sur les objets cron de Keda, vous pouvez suivre la documentation ici.
Mise à l'échelle avec une file de messages
Le but de ce deuxième exemple est de mettre à l'échelle automatiquement le nombre de pods qui vont venir consommer les messages d'une file RabbitMQ en fonction du nombre total de messages en attente.
Pour réaliser cet exemple, il faut ajouter le chart Helm RabbitMQ réalisé par Bitnami :
helm repo add bitnami https://charts.bitnami.com/bitnami
Pour le déployer, il est important de définir un utilisateur et un mot de passe pour remplacer ceux par défaut :
export RMQ_USERNAME=rmquser
export RMQ_PASSWORD=rmqpassword
helm install rabbitmq --set auth.username=$RMQ_USERNAME --set auth.password=$RMQ_PASSWORD bitnami/rabbitmq
On va attendre que le pod soit bien déployé :
kubectl get pods
NAME READY STATUS RESTARTS AGE
rabbitmq-0 1/1 Running 0 1m21s
Tout est bon, le pod est Ready.
On continue en créant le secret Kubernetes avec la chaine de connexion RabbitMQ. Dans notre cas, elle ressemble à ça : amqp://$RMQ_USERNAME:[email protected]:5672
echo -n "amqp://$RMQ_USERNAME:[email protected]:5672" | base64
Ce qui va donner une chaine de connexion en base64 que l'on va venir utiliser dans notre objet Secret ci-dessous :
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: rabbitmq-host
data:
rabbitmqHost: YW1xcDovL3JtcXVzZXI6cm1xcGFzc3dvcmRAcmFiYml0bXEuZGVmYXVsdC5zdmMuY2x1c3Rlci5sb2NhbDo1Njcy
EOF
Pour utiliser notre secret au sein de Keda, comme cela a été indiqué plus haut, il faut utiliser un objet de type TriggerAuthentication afin de le lier plus tard dans le ScaledObject.
cat <<EOF | kubectl create -f -
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: rabbitmq-trigger
spec:
secretTargetRef:
- parameter: host
name: rabbitmq-host
key: rabbitmqHost
EOF
On vient ensuite créer notre ScaledObject de type rabbitmq, vous trouverez dans la documentation l'ensemble des paramètres et leur signification.
cat <<EOF | kubectl create -f -
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-receiver
spec:
scaleTargetRef:
name: rabbitmq-receiver
triggers:
- type: rabbitmq
metadata:
queueName: hello
queueLength: "5"
authenticationRef:
name: rabbitmq-trigger
EOF
En suivant ce lien, vous trouverez un exemple en langage Python pour recevoir des messages dans RabbitMQ.
Ce qui intéressant ici, c'est de créer un ensemble de consommateurs en lien avec RabbitMQ qui vont venir lire la file de messages et plus il y aura de messages, plus le nombre de pods sera conséquent. Cela est défini avec queueLength, qui dans notre cas, tous les cinq messages, un pod sera ajouté.
À travers ce dépôt de code, j'ai fait un exemple en me basant sur le lien ci-dessus pour créer un déploiement d'un pod qui consommera les messages et un job qui va venir en ajouter un certain nombre (100 dans notre cas).
J'ai aussi ajouté les Dockerfile pour venir créer les images qui vont contenir toutes deux un script Python en fonction de l'action qu'elles doivent effectuer.
https://github.com/axinorm/keda-rabbitmq
Dès lors que l'ensemble des messages sont consommés, Keda va venir tuer les pods.
Ci-dessous le job a été exécuté, ce qui a pour conséquence que le ScaledObject de Keda va s'activer et créer 20 pods (car 100 messages viennent d'être ajoutés et que le queueLength est de 5) :
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
rabbitmq-0 1/1 Running 1 17h
rabbitmq-receiver-6bf68bb456-2ctqx 1/1 Running 0 40s
rabbitmq-receiver-6bf68bb456-2hwg2 1/1 Running 0 9s
rabbitmq-receiver-6bf68bb456-42hbh 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-4nqj8 1/1 Running 0 55s
rabbitmq-receiver-6bf68bb456-62d7l 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-6tm54 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-85kbd 1/1 Running 0 9s
rabbitmq-receiver-6bf68bb456-9fp6w 1/1 Running 0 55s
rabbitmq-receiver-6bf68bb456-dq8wx 1/1 Running 0 9s
rabbitmq-receiver-6bf68bb456-g2gg7 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-ghnlw 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-hg7l4 1/1 Running 0 55s
rabbitmq-receiver-6bf68bb456-hgbxx 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-jmj2w 1/1 Running 0 40s
rabbitmq-receiver-6bf68bb456-qrpb2 1/1 Running 0 60s
rabbitmq-receiver-6bf68bb456-rdqks 1/1 Running 0 24s
rabbitmq-receiver-6bf68bb456-scf9l 1/1 Running 0 40s
rabbitmq-receiver-6bf68bb456-vh6ct 1/1 Running 0 40s
rabbitmq-receiver-6bf68bb456-wvvxl 1/1 Running 0 9s
rabbitmq-receiver-6bf68bb456-z9lnb 1/1 Running 0 24s
Conclusion
Keda est le genre d'outil qu'il faut avoir sur son cluster Kubernetes pour être capable de contrôler la charge de travail. De par l'ensemble des connecteurs qu'il possède Keda peut se brancher sur un panel assez large de services, ce qui le rend presque indispensable quelle que soit la situation.
De plus pour faire des économies de CPU ou de RAM sur des petites machines comme un raspberry, il peut s'avérer très pratique.