GitLab CI et les pipelines enfants

Un peu d'histoire...
Le mois dernier, j'ai eu l'occasion de présenter mon talk au Voxxed Days - Luxembourg s'intitulant "Déployer de manière dynamique son code Terraform avec GitLab CI".
L'objectif principal était d'introduire différents outils, associés à Terraform et à mettre en place dans une chaîne CI/CD. Tout cela sans oublier de parler d'un contexte plus avancé introduisant les pipelines enfants.
Oui mais, qu'est-ce que c'est qu'une pipeline enfant ? C'est ce que je vais vous décrire dans la suite de cet article !
Ce sujet fait suite à un article précédent intitulé Une CI/CD prête à l'emploi pour Terraform avec GitLab CI.
Si vous souhaitez une introduction à GitLab CI et découvrir son fonctionnement, je vous encourage vivement à consulter cet article.
Les pipelines enfants
Les pipelines enfants sont une fonctionnalité de GitLab CI provenant de la famille des Downstream pipelines. Cette fonctionnalité est disponible sur l'ensemble des éditions de GitLab CI, de la version open source à l'édition entreprise.
Le concept est assez simple, la pipeline principale définie dans votre fichier .gitlab-ci.yml peut télécharger ou générer un autre fichier YAML ayant la structure d'une chaine automatisée GitLab CI composée de steps et de jobs dans le but d'être déclenchée par la pipeline principale.
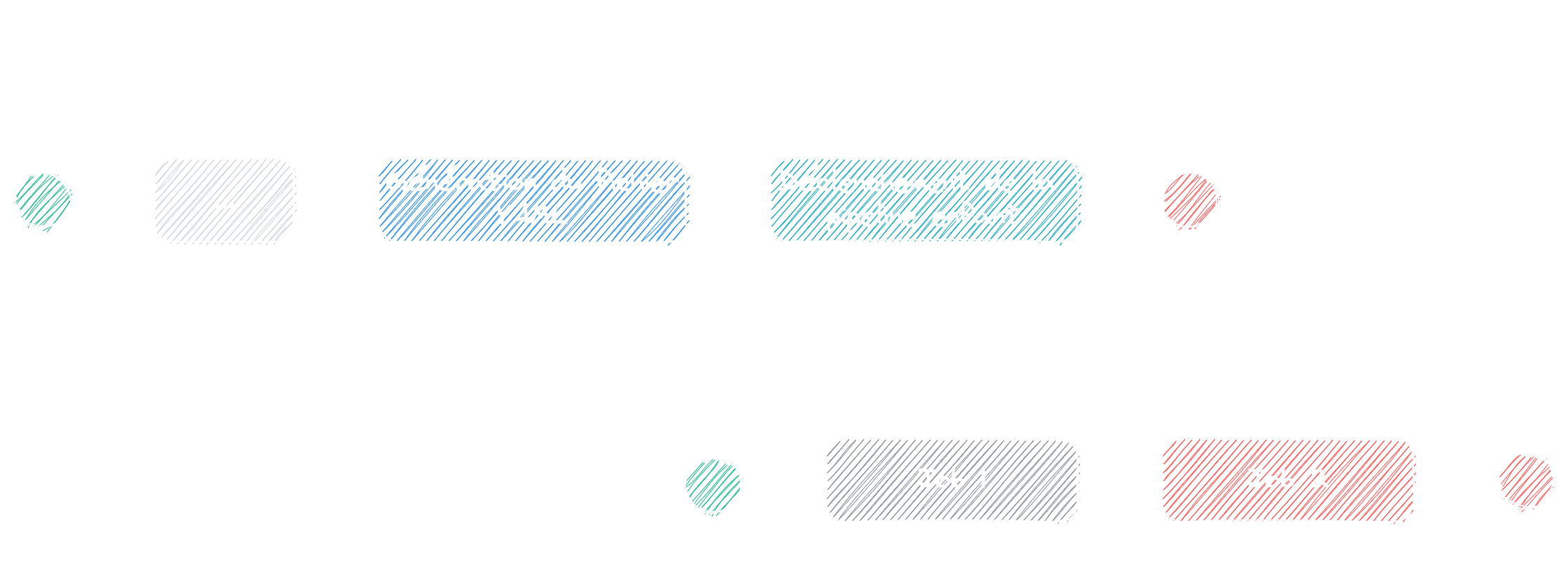
L'objectif est, pourquoi pas, de générer une sous-pipeline dynamiquement en fonction de fichiers (ou autres contenus) afin d'éviter de modifier le fichier .gitlab-ci.yml de la pipeline principale à chaque modification du code.
J'utilise ce concept principalement avec Terraform pour le déploiement d'infrastructure, la création d'images de machine virtuelle avec Packer et Ansible, mais aussi la création d'images de conteneur.
Par rapport à l'image ci-dessus, le fichier .gitlab-ci.yml de la pipeline principale ressemblerait à ça :
stages:
- generate
- deploy
generate:
stage: generate
image: [...]
script:
- [...] # Script de génération de la pipeline
artifacts:
paths:
- "pipeline-enfant.yml" # Fichier contenant la pipeline enfant à stocker
expire_in: 24 hour
deploy:
stage: deploy
trigger: # Déclenchement de la pipeline enfant avec le fichier associé
include:
- artifact: pipeline-enfant.yml
job: generate
needs:
- generate
L'étape generate se charge de créer le fichier YAML de la pipeline enfant au travers d'un script dans un langage défini dans l'objectif de le stocker avec le bloc artifacts. Ce fichier sera utilisé dans l'étape deploy.
Le job deploy quant à lui, avec l'instruction trigger interprétera le fichier pipeline-enfant.yml du job generate avec l'instruction trigger.
À noter que différentes configurations sont possibles pour ce type de bloc, notamment pour utiliser un fichier local ou déclencher une pipeline d'un autre dépôt de code.
Il est maintenant temps de continuer vers un cas concret avec Terraform.
Cas avancé avec Terraform
Lorsque l'on souhaite déployer plusieurs couches Terraform contenu dans un seul dépôt de code (mono-repo), il est important de visualiser de manière concrète l'ensemble des étapes plan et apply.
Surtout quand on dispose d'une multitude de fichiers .tfvars symbolisant l'instanciation d'une couche.
Vous pouvez retrouver ici un exemple d'utilisation de pipelines enfants avec Terraform.
Cet exemple se base sur le déploiement de ressources (folder et project) au sein d'une organisation Google Cloud.
La code Terraform se décompose comme tel :
- Le premier dossier
folderspermet de créer des dossiers au sein d'une organisation Google Cloud avec la possibilité d'ajouter des restrictions (Organization Policy) ; - Le deuxième dossier
projectspermet de déployer un projet avec une couche réseau (VPC).
Si l'on prend le cas des folders, il y aura deux fichiers à instancier (contenus dans le dossier configurations) pour cette couche :
prod.tfvarssandbox.tfvars
Ces deux fichiers .tfvars représentent la création de deux folders au sein d'une organisation sur Google Cloud. C'est la même chose pour la couche projects avec backend.tfvars, external-services.tfvars et tools.tfvars où le but sera de déployer des projects.
Le cas présenté est assez "simple", il se base uniquement sur deux couches pour faciliter la compréhension. Néanmoins, vous pouvez vous baser sur cet exemple pour déployer du code Terraform beaucoup plus conséquent.
Si l'on regarde de plus près le fichier gitlab-ci.yml, on s'aperçoit que celui-ci est composé de deux fichiers :
include:
- 'ci/check.gitlab-ci.yml'
- 'ci/terraform.gitlab-ci.yml'
Les jobs contenus dans ces deux fichiers s'associent aux étapes (steps) à savoir : check, generate ou deploy.
Vous l'aurez compris, ce qui nous intéresse particulièrement est l'étape generate qui est définie dans le fichier ci/terraform.gitlab-ci.yml.
La structure est sensiblement la même que celle présentée au-dessus :
generate-terraform-pipeline:
stage: generate
image: python:${PYTHON_IMAGE_VERSION}
before_script:
- pip install --no-cache-dir pyyaml jinja2
script:
- python3 ./ci/pipelines/generate_pipeline.terraform.py
artifacts:
paths:
- "*.pipeline.terraform.gitlab-ci.yml"
- generate_pipeline.terraform.log
expire_in: 24 hour
folders:
stage: deploy
trigger:
include:
- artifact: folders.pipeline.terraform.gitlab-ci.yml
job: generate-terraform-pipeline
needs:
- generate-terraform-pipeline
[...]
C'est donc le script python generate_pipeline.terraform.py qui se charge de créer le ou les fichiers YAML correspondant aux différentes couches définies dans la configuration pipeline_config.terraform.yaml.
La taille du fichier est relativement petite, cela représente moins d'une centaine de lignes. Le but de celui-ci est d'identifier les fichiers .tfvars contenus dans le dossier configurations.
Pour rappel, ces fichiers .tfvars représentent les instances des différentes couches du code Terraform comme mentionné plus haut.
La structure du fichier de configuration est facilement compréhensible :
layers:
folders:
path: terraform/folders
projects:
path: terraform/projects
Les couches (layers) sont définies avec le chemin du code Terraform défini dans path.
Le fichier pipeline_template.terraform.yaml.j2 est un modèle (template) en Jinja qui permet de créer autant de jobs terraform-plan et terraform-apply qu'il y a de fichiers .tfvars.
{% for tfvars_file in tfvars_files -%}
{% set filename = tfvars_file.split('.')[0] -%}
{{ filename }}-terraform-plan:
extends: .default_terraform_job
stage: plan
script:
[...]
{{ filename }}-terraform-apply:
extends: .default_terraform_job
stage: apply
script:
[...]
{% endfor -%}
Il est tout à fait possible d'utiliser autre chose que le Python, c'est pour ma part un choix personnel mais n'hésitez pas à adapter en fonction de votre aisance avec un langage particulier. L'avantage de ce dernier est le mécanisme de templating en Jinja facile et rapide à utiliser sans casser la lisibilité du code.
Voici ce que ça donne quand on exécute une pipeline au sein de GitLab CI :
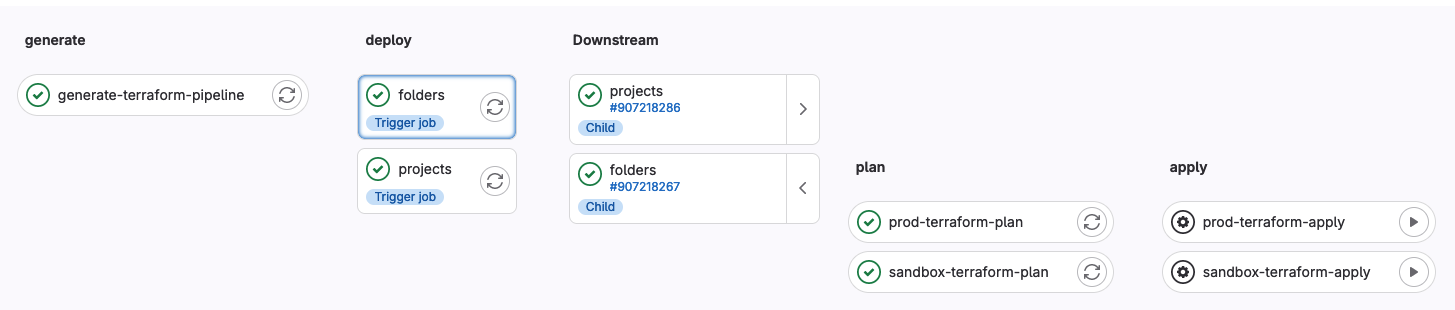
Le résultat est conforme à nos attentes : il est possible de déclencher manuellement des apply sur l'ensemble de nos fichiers .tfvars contenus dans nos couches d'infrastructure sans oublier de visualiser le plan avant cette manipulation.
Quelques compléments
Paramétrage avancé
Pour aller plus loin, il est possible d'ajouter quelques options intéressantes :
-
Ajouter un mécanisme qui vérifie les fichiers
.tfvarsmodifiés, ce qui évite d'avoir une pipeline complète et permet de mettre à jour uniquement les composants impactés par les modifications. -
Intégrer un ou plusieurs tests Terratest pour valider la non-régression d'une couche ou d'un module lors d'une modification d'un fichier
.tf. Il est possible de réaliser cela avec lesrulesetchanges. -
Réaliser une étape de synthèse par rapport à l'ensemble des plans de Terraform afin d'avoir une vue d'ensemble sur ce qui est à jour ou non.
Évidemment cette liste n'est pas exhaustive, ce sont quelques idées pour compléter l'exemple du dessus.
Autres cas d'utilisation
Pour clôturer le tout, j'utilise les pipelines enfants dans d'autres cas d'utilisation :
- Création d'images de machine virtuelle avec Packer et Ansible ;
- Création d'images de conteneur avec Docker ou Kaniko.
L'idée est toujours la même : Se baser sur des fichiers .hcl pour Packer ou Dockerfile pour les conteneurs afin de générer une multitude d'étapes permettant la construction des différentes images.
On s'approche, avec cette méthode, d'une usine de création d'images entièrement automatisée.
Voici un exemple sur la création d'images de machine virtuelle avec Packer :
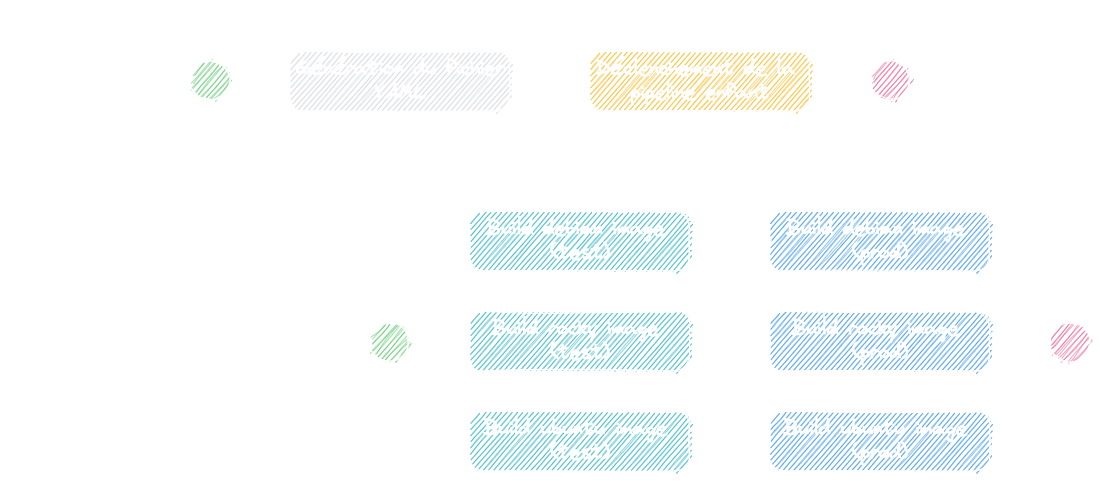
Comme vous pouvez remarquer, une pipeline enfant est générée par catégorie d'images (ici GitLab Runner), les fichiers .pkr.hcl représentent les différents types de système d'exploitation.
Tout comme Terraform au-dessus, ajouter un fichier .pkr.hcl ajustera le nombre de jobs GitLab CI à générer.
Le mot de la fin
Vous l'aurez compris, ce concept peut s'intégrer dans beaucoup de cas d'utilisation. Il permet de construire une chaîne CI/CD robuste, mais aussi dynamique en évitant la maintenance du fichier de GitLab CI à chaque ajout ou suppression de contenu.
Cette fonctionnalité a encore plus de valeur dans le cas d'utilisation d'un seul dépôt de code pour plusieurs usages (centralisation du code de l'infrastructure, des applications, etc.) pour compartimenter et scinder la pipeline principale facilitant la compréhension et par conséquent, son évolutivité.
Il me reste un chapitre sur la thématique GitLab CI, celui de l'installation des runners. Je vous donne rendez-vous dans un futur article pour discuter de ce sujet !